 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOCO: Benchmarking Semantic Object Correspondence in Vision Foundation Models
Jun 01, 2026Measuring structured object understanding in vision foundation models remains challenging due to inconsistent evaluation protocols and limited part-level supervision. Semantic correspondence (SC) evaluates this capability by testing whether object parts can be matched across instances and categories under large variations in appearance, viewpoint, and geometry. To enable a systematic SC evaluation, we introduce SOCO, a new benchmark for Semantic Object Correspondence that introduces a taxonomy of correspondence types and provides consistent, functionally meaningful keypoint annotations across 100 categories and over 1M correspondence pairs. In addition, SOCO includes keypoint language descriptions, enabling the evaluation of large vision-language models (LVLMs) and their fine-grained part-level understanding. Comprehensive experiments reveal that (i) vision foundation backbones encode strong semantic structure but transfer correspondences poorly across related categories and only partially capture object-part position, (ii) LVLMs are stronger at text-prompted part localization than at visual-reference cross-image matching, exposing a gap between language-grounded localization and fine-grained visual correspondence, and (iii) correspondence performance predicts performance on dense downstream tasks, including segmentation, tracking, 3D pose estimation, and 3D detection, more strongly than ImageNet classification. Together, these findings position SOCO as a benchmark for structured, part-level representation quality in vision and multimodal foundation models.
Geometry Matters: 3D Foundation Priors for Learning Semantic Correspondence
May 28, 2026Foundation features from self-supervised vision models and text-to-image diffusion models have proven effective for semantic correspondence estimation. However, because these features are learned primarily from 2D image objectives, they lack explicit 3D awareness and often confuse symmetric object sides, repeated parts, and visually similar structures that are distinct in 3D. We introduce a 3D-aware post-training framework that goes beyond available 2D foundation features by incorporating priors from 3D foundation models. Given an image, our method uses SAM3D to estimate object geometry and pose, and refines the pose through render-and-compare optimization. Subsequently, we render PartField descriptors from the reconstructed geometry into the image plane based on the estimated object pose. The resulting geometry-aware feature maps complement DINO and Stable Diffusion features, while geodesic distances on the reconstructed shapes enable reliable filtering of candidate correspondences. We use the filtered matches as supervision to train a lightweight adapter on top of DINO and Stable Diffusion for semantic correspondence. In contrast to prior post-training approaches that require pose annotations and rely on coarse spherical geometry, our method automatically obtains instance-specific 3D structure and uses it to guide correspondence learning. Experiments show that our approach improves semantic correspondence over the prior methods while reducing manual geometric supervision. Code and model can be found at https:/github.com/GenIntel/3D-SC.
CRONOS: Benchmarking Counterfactual Physical Consistency in Video Models
May 22, 2026Video prediction is increasingly viewed as a path toward generalizable world models, yet it remains unclear whether these systems learn underlying causal structure or merely exploit superficial visual correlations for future prediction. We introduce CRONOS, an intervention-based benchmark designed to evaluate counterfactual physical consistency: whether a model's predictions of physical events respond appropriately to controlled changes in the visual input, such as variations of scene context, viewpoint, object appearance, and object category. Built in a photorealistic Unreal Engine environment, CRONOS enables controlled, high-fidelity generation of videos across diverse scenes and dynamics. In contrast to previous benchmarks, CRONOS systematically intervenes on four key factors - viewpoint, scene, object category, and object appearance - while keeping the underlying physical event type, such as a collision, occlusion, or fall, fixed. Our evaluation of recent open-source video generators reveals substantial failures in counterfactual physical consistency: prediction quality for the same physical event type is affected by appearance, environment, and, particularly by viewpoint changes. CRONOS provides a controlled and reproducible testbed for diagnosing how the quality of generated videos changes for different interventions, establishing a concrete target for developing models that perform consistently across changes of multiple conditions. The dataset and code are available at our project page.
Attention (as Discrete-Time Markov) Chains
Jul 23, 2025We introduce a new interpretation of the attention matrix as a discrete-time Markov chain. Our interpretation sheds light on common operations involving attention scores such as selection, summation, and averaging in a unified framework. It further extends them by considering indirect attention, propagated through the Markov chain, as opposed to previous studies that only model immediate effects. Our main observation is that tokens corresponding to semantically similar regions form a set of metastable states, where the attention clusters, while noisy attention scores tend to disperse. Metastable states and their prevalence can be easily computed through simple matrix multiplication and eigenanalysis, respectively. Using these lightweight tools, we demonstrate state-of-the-art zero-shot segmentation. Lastly, we define TokenRank -- the steady state vector of the Markov chain, which measures global token importance. We demonstrate that using it brings improvements in unconditional image generation. We believe our framework offers a fresh view of how tokens are being attended in modern visual transformers.
CNS-Bench: Benchmarking Image Classifier Robustness Under Continuous Nuisance Shifts
Jul 23, 2025An important challenge when using computer vision models in the real world is to evaluate their performance in potential out-of-distribution (OOD) scenarios. While simple synthetic corruptions are commonly applied to test OOD robustness, they often fail to capture nuisance shifts that occur in the real world. Recently, diffusion models have been applied to generate realistic images for benchmarking, but they are restricted to binary nuisance shifts. In this work, we introduce CNS-Bench, a Continuous Nuisance Shift Benchmark to quantify OOD robustness of image classifiers for continuous and realistic generative nuisance shifts. CNS-Bench allows generating a wide range of individual nuisance shifts in continuous severities by applying LoRA adapters to diffusion models. To address failure cases, we propose a filtering mechanism that outperforms previous methods, thereby enabling reliable benchmarking with generative models. With the proposed benchmark, we perform a large-scale study to evaluate the robustness of more than 40 classifiers under various nuisance shifts. Through carefully designed comparisons and analyses, we find that model rankings can change for varying shifts and shift scales, which cannot be captured when applying common binary shifts. Additionally, we show that evaluating the model performance on a continuous scale allows the identification of model failure points, providing a more nuanced understanding of model robustness. Project page including code and data: https://genintel.github.io/CNS.
Do It Yourself: Learning Semantic Correspondence from Pseudo-Labels
Jun 05, 2025Finding correspondences between semantically similar points across images and object instances is one of the everlasting challenges in computer vision. While large pre-trained vision models have recently been demonstrated as effective priors for semantic matching, they still suffer from ambiguities for symmetric objects or repeated object parts. We propose to improve semantic correspondence estimation via 3D-aware pseudo-labeling. Specifically, we train an adapter to refine off-the-shelf features using pseudo-labels obtained via 3D-aware chaining, filtering wrong labels through relaxed cyclic consistency, and 3D spherical prototype mapping constraints. While reducing the need for dataset specific annotations compared to prior work, we set a new state-of-the-art on SPair-71k by over 4% absolute gain and by over 7% against methods with similar supervision requirements. The generality of our proposed approach simplifies extension of training to other data sources, which we demonstrate in our experiments.
Common3D: Self-Supervised Learning of 3D Morphable Models for Common Objects in Neural Feature Space
Apr 30, 20253D morphable models (3DMMs) are a powerful tool to represent the possible shapes and appearances of an object category. Given a single test image, 3DMMs can be used to solve various tasks, such as predicting the 3D shape, pose, semantic correspondence, and instance segmentation of an object. Unfortunately, 3DMMs are only available for very few object categories that are of particular interest, like faces or human bodies, as they require a demanding 3D data acquisition and category-specific training process. In contrast, we introduce a new method, Common3D, that learns 3DMMs of common objects in a fully self-supervised manner from a collection of object-centric videos. For this purpose, our model represents objects as a learned 3D template mesh and a deformation field that is parameterized as an image-conditioned neural network. Different from prior works, Common3D represents the object appearance with neural features instead of RGB colors, which enables the learning of more generalizable representations through an abstraction from pixel intensities. Importantly, we train the appearance features using a contrastive objective by exploiting the correspondences defined through the deformable template mesh. This leads to higher quality correspondence features compared to related works and a significantly improved model performance at estimating 3D object pose and semantic correspondence. Common3D is the first completely self-supervised method that can solve various vision tasks in a zero-shot manner.
Normalizing Flows on the Product Space of SO Manifolds for Probabilistic Human Pose Modeling
Apr 08, 2024Normalizing flows have proven their efficacy for density estimation in Euclidean space, but their application to rotational representations, crucial in various domains such as robotics or human pose modeling, remains underexplored. Probabilistic models of the human pose can benefit from approaches that rigorously consider the rotational nature of human joints. For this purpose, we introduce HuProSO3, a normalizing flow model that operates on a high-dimensional product space of SO(3) manifolds, modeling the joint distribution for human joints with three degrees of freedom. HuProSO3's advantage over state-of-the-art approaches is demonstrated through its superior modeling accuracy in three different applications and its capability to evaluate the exact likelihood. This work not only addresses the technical challenge of learning densities on SO(3) manifolds, but it also has broader implications for domains where the probabilistic regression of correlated 3D rotations is of importance.
Sample-Specific Output Constraints for Neural Networks
Mar 23, 2020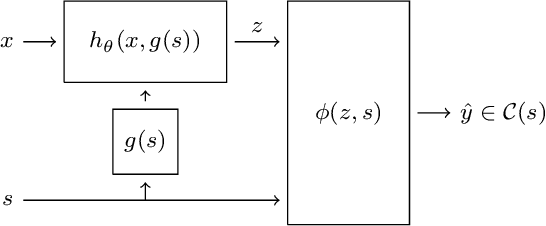
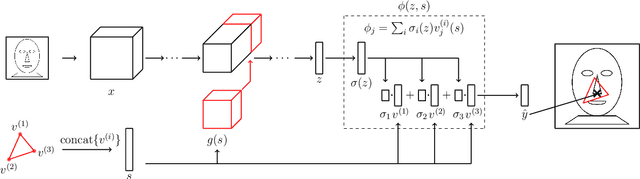
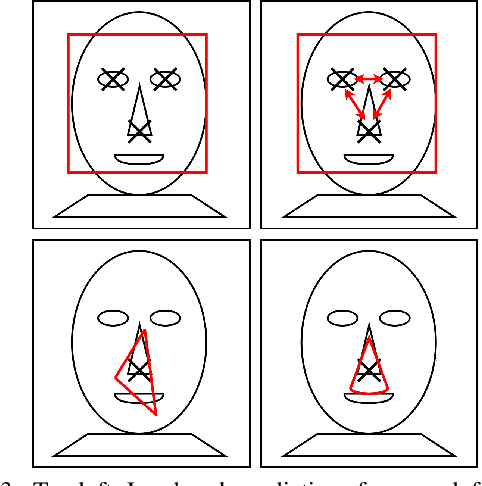
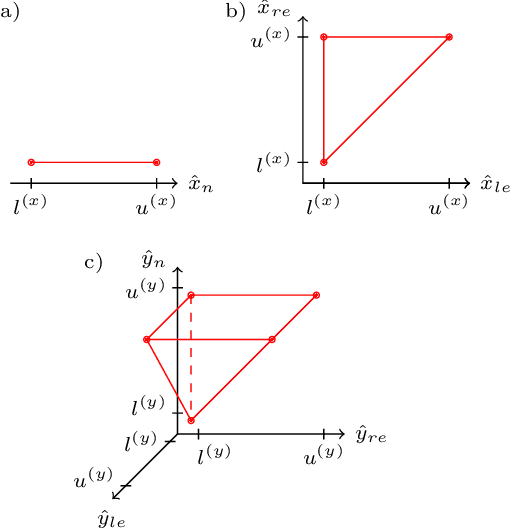
Neural networks reach state-of-the-art performance in a variety of learning tasks. However, a lack of understanding the decision making process yields to an appearance as black box. We address this and propose ConstraintNet, a neural network with the capability to constrain the output space in each forward pass via an additional input. The prediction of ConstraintNet is proven within the specified domain. This enables ConstraintNet to exclude unintended or even hazardous outputs explicitly whereas the final prediction is still learned from data. We focus on constraints in form of convex polytopes and show the generalization to further classes of constraints. ConstraintNet can be constructed easily by modifying existing neural network architectures. We highlight that ConstraintNet is end-to-end trainable with no overhead in the forward and backward pass. For illustration purposes, we model ConstraintNet by modifying a CNN and construct constraints for facial landmark prediction tasks. Furthermore, we demonstrate the application to a follow object controller for vehicles as a safety-critical application. We submitted an approach and system for the generation of safety-critical outputs of an entity based on ConstraintNet at the German Patent and Trademark Office with the official registration mark DE10 2019 119 739.